Symmetric Cryptographic Systems
Entropy
Claude Shannon pioneered the concept of entropy within signals processing. He said "a signal that is totally predictable carries no information". The idea of entropy is the difference in the signal between what is predicted and the actual values we get from the system.
Shannon hypothesised this in terms of "bits" of entropy. For a system that contains \(N\) bits of information, then there are \(2^N\) possible characters for that system. Given a set of symbols \(A = \{a_1, a_2, \dots, a_i\}\), then the entropy of this source is:
Entropy is simply the measure of how much information is encoded in a message.
Compression
Shannon also hypothesised that the number of bits which was needed to binary code a message was given with the following formula:
For a message ABAESEDA, we can calculate \(P(X=A)\) as \(3/8 = 0.375\), and similarly for B, D, E, S. Given the probabilities of each of these occurring, we calculate the entropy \(H(X)\) as 2.15 bits.
Given the entropy, then we can calculate the minimum number of bits needed as:
We typically use ASCII for simple file text encoding, which makes use of 8 bits per character. As we encode 8 characters, using ASCII, we would require 64 bits. There is a difference between the 17.2 bits and the 64 bits, which means we are using redundant data to encode the file. We can thus compress the file to save space.
For a string XXXXYXXXXZXXXXTXXXXW, the entropy of the string \(H(X)\) is much lower, as there is a lot of repeated X characters. Using the formula for entropy, we get that the string has 1.121 bits, and thus with \(n=20\), we should be able to store the string in just 22.43 bits of space. Again, with ASCII, this would be \(8 \times 20 = 160\) bits.
Symmetric Enciphering
When using an encryption algorithm, we use an encryption key to transform the plaintext into a ciphertext. The decryption algorithm uses a decryption key to transform the ciphertext back into a plaintext.
Shared key systems are where both sender and receiver use the same key, which must remain private. These systems can also be called symmetric systems. Examples include DES, Triple-DES, Twofish, and Rijndael.
Stream vs. Block Ciphers
Block Cipher
A block cipher works on a block of text as a whole, and each block is used to produce a ciphertext block of equal length. A block length of 128 bits or more is usually used. AES uses a block cipher. The encryption algorithm takes \(b\) bits of the plaintext, and a key \(K\). It then produces \(b\) bits of ciphertext.
graph LR
A["`Plaintext ($b$ bits)`"] --> C[Encryption Algorithm];
B(("`Key ($K$)`")) --> C;
C --> D["`Ciphertext ($b$ bits)`"];Stream Cipher
A stream cipher, on the other hand is where one bit or byte is encrypted/decrypted at a time. In a stream cipher, we generate a bit stream from the key \(K\), and this is typically XORed with the plaintext \(P\), using \(k_i \oplus p_i = c_i\). As something XORed with the same key again will yield the original text, when we then come to decrypt the stream, we can simply use the same key \(K\) and algorithm to generate \(k_i\), then use \(k_i \oplus c_i = p_i\).
Here, \(\oplus\) is shorthand for XOR. Stream ciphers include XOR ciphers, RC4 A5/1 and A5/2 (both of which have been used in GSM encryption).
graph LR
A(("`Key ($K$)`")) --> B[Bitstream generation algorithm];
C(("`Plaintext ($p_i$)`")) --> D["`$\oplus$`"];
B -->|"`Cryptographic Bitstream ($k_i$)`"| D;Problems with Symmetric Ciphers
Symmetric keys have the issue in that once keys are compromised, then interceptors can decrypt any ciphertext that they have acquired. Therefore, we change the keys somewhat frequently (rekeying) to limit the total damage.
Futhermore, it is difficult to transmit the keys to the third party, and the key must be transmitted securely to prevent snooping.
Kirchhoff's Principle
"the cipher must not depend on the secrecy of the mechanism, it must not matter if it falls into the hands of the enemy."
This was an issue recently with TETRA, as they had several proprietary encryption algorithms. These algorithms were unable to be audited by the public, and once cryptanalysts got hold of them through reverse engineering of the firmware on a TETRA-enabled device, they were able to break the encryption. Had the algorithms been published for review before standardisation, then it would be possible for the mechanism to be attacked, and thus those algorithms would have been re-thought.
What Must Be Kept Secret
TODO think it's just the keys
Formal Definitions
A cipher is defined over \((K,M,C)\) as a pair of algorithms \((E,D)\), where \(E: K \times M \to C\) and \(D : K \times C \to M\), such that \(E\) and \(D\) satisfy the following consistency equation:
Essentially, for all inputs and all keys, decrypting an encrypted message will always yield the original message.
Shannon Perfect Secrecy
A cipher \((E,D)\) over \((K,M,C)\) has perfect secrecy iff:
So, given a ciphertext, I would be unable to deduce whether the message is \(m_1\) or \(m_2\) r any other \(m\), so we can learn nothing about the plaintext from the ciphertext.
If a cipher has Shannon perfect secrecy, then there is no cipher text only attack, although some other attacks may still be possible.
Application to Shift Ciphers
We can map the message letters to numbers, e.g., \(a=1,b=2,\dots\). We then encrypt the message by shifting each letter in the message by \(K\) positions, where \(k\) is the key:
$$ c = E_K(p) = (p+k) \mod 26 $$ For \(m = \text{HELLO}, k=1, c=\text{IFMMP}\).
We can then ask if the shift cipher satisfies SPS for messages with length \(\ge 2\).
If we take \(m_1 = \text{AC}\), \(m_2 = \text{AZ}\), \(c=\text{BD}\), and assume that all keys have the same probability \(Pr[E(k,m_1) = c] = \frac{1}{26}\) for the initial message, then \(\forall k \in K\), \(E(k,m_2) \ne c\), and so \(Pr[E(k,m_2) = c] = 0\).
This would violate the SPS property of the shift cipher and so we can attack it based on the ciphertext only.
One Letter Long Message Proof
Not sure this is correct
For a one-letter long message, the shift cipher is immune to the attack, as the probability of generating each message \(m_1, m_2, \dots, m_i\) is the same. The probability of generating each ciphertext from \(m_1\) is also \(\frac{1}{26}\), and the same for \(m_2\).
Application to Permutation Ciphers
We can assume that a permutation cipher used is a 3-letter English word. If we use \(C= igd\), then \(M=[gdi,gid,idg,igd,dig,dgi]\), then we have:
but,
One Time Pads
A one time pad is defined in the following way:
For \(n=3\), we have:
$$ M=C=[000,001,010,011,100,101,110,111] $$ We can then define \(m=010\) and \(k=111\). We do a simple XOR: \(010 \oplus 111 = 101\).
Are they Secure?
For a message to map to a cipher with an OTP, the key must have the same length as the message. We can initially look at the powerset when \(n=1\):
In this instance, \(0\) can be converted to \(1\) using the key \(0\), and the key \(1\) does not work, as \(0 \oplus 0 = 1\). The XOR function cannot produce a different mapping from \(m\) to \(c\) with a different key, and if we reuse the same \(m\), but a different key, we will always get a different \(c\).
The size of \(\{k \in K : E(k,m) = c\} = 1\), as for each key, there is exactly one mapping from the \(m\) to the \(c\) via that key. This is an important concept in the idea of a one-time pad.
\(\forall m,c\), the probability that \(E(k,m) = c\) is going to be \(\frac{1}{|K|}\), where \(|K|\) denotes the length of the key.
Therefore, the message has perfect secrecy, provided that the key is only used once and that the key is randomly distributed.
For a message to have SPS, the key must also be as long as the message \(|K| \ge |M|\), otherwise we do not have perfect secrecy.
Perfect Secrecy vs Computational Secrecy
Shannon took a very information-theoretical view in his definition. We relax the notion from an information-theoretic secrecy to computational secrecy.
Information theoretic security requires that given a ciphertext \(c\), every plaintext \(p\) is just as likely as each other. Computational secrecy on the other hand just says that no efficient algorithm exists that can deduce which out of a ciphertext and two plaintexts is more likely.
A reminder of SPS:
Computational perfect secrecy is very similar:
Both notions assume that the attacker can only observe the ciphertexts.
Once again, the \((k \stackrel{R}{\leftarrow} K)\) just means that \(k\) is randomly (\(R\)) chosen from the set \(K\).
Deterministic vs Random Functions
A function \(D\) is deterministic if it always produces the same output if the input doesn't change. A random function \(R\) produces different outputs based on the same inputs.
Pseudorandom Functions and Permutations
We have pseudorandom functions which are defined over \((K, X, Y)\) such that \(F: K \times X \rightarrow Y \iff \exists \text{an efficient algorithm to evaluate }F(k,x)\).
For a pseudorandom permutation defined over \((K,X)\), then the permutation \(E: K \times X \rightarrow X\). This also has some conditions:
- there is an efficient deterministic algorithm to evaluate \(E(k,x)\)
- The function \(E(K, \cdot)\) is one-to-one
- There is an efficient inversion algorithm \(D(k,y)\)
Any PRP is also a PRF, but a PRP is a PRF where \(X=Y\) and can be efficiently inverted. A PRF does not have to map to the same space, nor does it have to be invertible.
Example PRPs
AES-128 is an example of a PRP as is takes a key \(K\) and a block \(X | X = K = \{0,1\}^{128}\)
For 3DES, we have a similar idea, but \(X=\{0,1\}^{64}, K=\{0,1\}^{168}\).
Semantic Security of PRPs
A function \(E\) is semantically secure if for all "efficient" algorithms \(A\), the adversary \(Adv\), given \(E\) and \(A\) is negligible. We define this as:
where \(Exp\) denotes the experiment performed on the message. $$ { (m_0, m_1) | m_0,m_1 \in M , length(m_1) = length(m_2) } $$
Secure PRPs
Given a function \(P : K \times X \to \{0,1\}^8\) as a secure PRP. Is the following \(Y\) a semantically secure PRP?
Not sure if this is correct
The lecture slides and indeed the question here include a mapping from \(X\) to \(X \cup \{ 001000101 \}\). The answer assuming this is not a typo is given just below, and the case where it is a different 8-character bitstring in \(X\) is given below.
Not a PRP
For an individual \(Y\) not in a bitstream, we would be able to establish whether the answer is zero, by simply looking at the length of the cipher returned. \(Y\) is therefore not a PRP at all, as the answer space is not \(X\) as it is \(X \cup \{ 001000101 \}\). We could call it a PRF, however, that maps from \(X \to Y\)
PRP
There is no way to distinguish between the bitstream \(001000101\) from either \(Y\) or at random from \(P(k,x)\). If the function is truly random, then there would be a marginally higher incidence of \(001000101\) in the ciphertext, as the likelihood of mapping to that number would be twice as high as any other function.
Each of the keys in \(P\) would be \(1/256\) likely to occur. In this instance though, the probability of each key in \(P\) occuring would be \(1/257\), and a \(2/257\) chance that the cipher would be
Construction of Ideal Block Cipher
A block cipher would include a truly random permutation of each of the bits. We view each possible block as a giant character in the alphabet that comprises \(2^N\) gigantic characters. For something like \(N=4\), the alphabet is \(2^4\) giant characters in size (16 in this instance). The numbers of mappings that exists is therefore \(2^N!\), as from the first, we can map to the rest, all bar the first one. Then the second one can map to all too.
For a key size 4 (with 16 elements), we can map from \(A_1 \to A_2, A_1 \to A_3, A1 \to A_4, \dots, A_1 \to A_{16}\) then the same for the second element mapping. There are thus \(16!\) factorial ways to map.
The key size required for this would be at minimum 45 bits (from \(\log_2(2^N!)\) bits. For AES, this would be \(\log_2(2^N!) \approx N \times 2^N \approx 10^{21}\) bits \(\approx 10^{11}\)GB.
Confusion and Diffusion
Shannon extended his notion of perfect secrecy to include two new terms: confusion and diffusion. He suggested the use of both substitution and permutation, each of which is responsible for confusion and diffusion, respectively.
Diffusion is the dissipation of the redundancy of the plaintext by spreading it out over the ciphertext. Confusion is the process of obscuring the relationship between the ciphertext and the plaintext in order to hide any statistical patterns.
DES
DES, or the data encryption standard algorithm, was and still is a commonly used block cipher. In 1971, IBM developed an algorithm called LUCIFER, operating on a block of 64 bits, using a 128-bit key. In 1973, the NBS ask for block cipher proposals. IBM submits a variant of LUCIFER.
In 1976, NBS adopts DES as a federal standard, with a key length of 56 bits, and a block length of 64 bits. In 1997, DES was broken by exhaustive search, and so a replacement was needed.
In 2000, NIST adopts the Rijndael algorithm as AES, replacing DES. AES is still the most common symmetric cipher in use today.
Feistel Structure
This was a proposal by Horst Feistel to avoid the complexity problem of an ideal block cipher. The approach was based on the Shannon ideas of diffusion and confusion. It may seem simple now, but the idea was that the execution of two or more simple ciphers in sequence leads to a much more cryptographically secure solution than either of the ciphers alone. Feistel employed both substitution and permutation.
The structure of the cipher initially takes the plaintext, then splits the data into two equal pieces, \(L_0\) and \(R_0\). The key is split into a specific number of subkeys, for each round.
For each round \(i=0,1,\dots,n\), we compute \(L_{i+1} = R_i, R_{i+1} = L_i \oplus F(R_i, K_i)\).
The ciphertext at this point is then \((R_{n+1}, L_{n+1})\). The Wikipedia diagram for this is good (Amirki, CC BY-SA 3.0):

Proof Bits and Claims
Essentially given some \(R_i, L_i\), we need to be able to find \(R_{i-1}, L_{i-1}\). To prove this, we have the following:
Operation Principles
A Feistel network takes in a plaintext which is \(2w\) bits long, and some key \(K\). The plaintext is split into two halves, data is passed through \(n\) rounds of processing, then recombined to produce the ciphertext.
Each round has the same structure. The left half of the data has some substitution performed. Some function \(F\) is performed on the right half of the data then XORed with the left half. We then do a final pass that requires the two halves of the data interchange.
Parameters
Feistel ciphers have a number of parameters that we can alter to create our own version of the cipher. The first is the block size. Larger blocks are more secure, but have speed penalties. Within DES, 64-bit blocks are heavily used. AES now uses 128-bit and 256-bit blocks.
We can also configure the number of rounds to do. More rounds are more secure, but again have some speed penalties. We want to make it so that the time to decrypt is reasonable but also that our data is similarly secure.
Furthermore, we can configure the subkey generation algorithm, it doesn't have to be simple at all. The round function is the \(R\), which we feed in both the subkey and the text from the \(L_{n-1}\) to.
The DES Algorithm
DES is a Feistel cipher with 16 rounds, a block size of 64, and a key length of 56. The \(F\) function is specific to DES and derives round keys uniquely. It works as a Feistel cipherm with the \(F\) function taking 32 bits, then expanding it to 48 bits. This is then combined with the round key of 48 and XORed. Following this, we then reduce the 48 bits back to 32 bits through a substitution/choice table, then perform another permutation.
The \(F\) Function
This is then XORed as usual with the left side of the equation, to yield \(R_i\) from \(R_{i-1}\). The \(F\) function, more specifically, is of the following form:
Permutations (\(P\) Function)
The permutation function is a fixed known mapping from 32 bits to 32 other bits. This part of the algorithm is publicly defined. The initial permutation is a simple lookup table, and the inverse permutation is the reverse of this table.
Substitutions (\(S\) Functions)
There is also the compression permutation, which is publicly known and maps a known subset of 56 bits to 48 bits in the output. This is invertible, because we use a combination of 6 bits to map to 4 in the output. If we did not use all information here, then it wouldn't be invertible and we'd have an issue.
The \(S\) function is \(S_i: \{0,1\}^6 \to \{0,1\}^4\). Each of the S-boxes is a 4x16 table, where each row is a permutation of 0-15. The outer bits 1&6 of the input select one of the four rows (\(2^2 = 4\)), then the inner 4 bits are used to select a column (\(2^4 = 16\)).
There are 8 different lookup tables dependent on the box that we are using. \(S\) has to be picked carefully to ensure that the function is not linear. If \(S\) and \(P\) were chosen at random, then we would have a linear function, allowing key recovery with \(\approx 2^{24}\) outputs. Therefore, there could be some fixed binary matrix for DES which given enough plaintexts and ciphertexts can be used to compute the secret key.
The first rule is that no output bit should be close to a linear function of the input bits.
Expansion Permutation (\(E\) Function)
This is another easy public bit of the algorithm. We take the initial inputs to the function, then some of the bits go to multiple bits in the output. This, again is simply implemented with a lookup table.
Design Controversies
Being a brainchild of the US Government, they were bound to want to have some sort of backdoor engineered into the protocol such that they could decrypt any message they wanted but with everyone else thinking the protocol was secure.
The criteria behind the design of the round function and key schedules (how each round key was chosen) were not public knowledge, although their final design was as otherwise there would only be proprietary implementations of the protocol which would eventually be reverse engineered anyway.
DES also has a number of weak keys. Luckily this set of keys is few and can be easily avoided in the implementation. DES was also criticised for an inadequate key length, even in 1975 before being adopted as a standard. There are some claims that the NSA insisted on this key length but this has not been publicly confirmed.
Strengths of DES
DES has a strong avalanche effect, which is what we want to see out of both an encryption and a hashing algorithm. Small changes in the plaintext of the key changes the ciphertext a lot. Within DES, the average change of 1 bit in the plaintext affects 34 bits in the ciphertext, and 1 bit in the key affects 35 bits in the ciphertext on average.
Due to the design, DES incorporates both diffusion and confusion, which need to be mixed to generate a strong encryption algorithm. Decryption is also performed in exactly the same way as encryption, with only the key order reversed, so hardware designers can add extensions for specific DES instructions that can use the same silicon in both ways (compared to e.g., AES which has 4 instructions in x86).
Attacks
Theoretical
If keyspace is \(2^{56}\), with 1M processors with 1M keys per second, then we can test \(10^6 \times 10^6 = 10^12\) keys per second. The keyspace is \(2^{56} \approx 7.21\times 10^{16}\).
Therefore, if we divide the keyspace by our search speed, this would be the time to exhaust the entire keyspace \(\frac{7.21\times10^{16}}{10^{12}} = 72057\) seconds, or 20 hours.
In terms of the probability, however, on average, we would encounter the key that matched the plaintext after only half the search time, or about 10 hours. The worst case if the key is the last one we try would still be 20 hours though.
Brute Force
Many cryptographers criticised the keyspace of DES and thus set out to either demonstrate a theoretical or a practical attack on DES. Should a successful, cheap attack be possible, then governments would be able to decrypt any DES ciphertexts with ease. A list of these is given below:
| Year | Technique | Implemented | Cost ($) | Search Time |
|---|---|---|---|---|
| 1977 | Diffie Hellman | No | 20M | 20h |
| 1993 | Wiener | No | 1M | 7h |
| 1997 | Rocke Verser et al. | Yes | ? | 3mo |
| 1998 | EFF | Yes (90B/sec) | 250K | 56h |
| 2008 | COPACOBANA SciEngines GmbH | Yes | 10K | <24h |
Multiple Encryption
The DES algorithm's main flaw is that the keyspace is too small. The keyspace of \(2^{56}\). NIST knew this, and after the EFF showed their brute force cracker the algorithm was superseded with AES as an alternative.
At this stage, however, financial organisations had seen that DES was reasonably secure, and in all the years of use had not been properly broken. Therefore, if possible, they wanted to continue using DES but make use of a larger keyspace.
Double-DES
Therefore, the solution as an alternative to transitioning to AES was to use DES with multiple keys. Naïvely, we could just encrypt with two keys \(C = E_{K2}(E_{K1}(P))\). You would assume that this would double the key length, and thus the keyspace from \(56 \times 2 = 112\) bits, with keyspace \(2^112\), which isn't all that far from the AES keyspace.
Meet-in-the-Middle Attack
Unfortunately, this is possible to bypass with what is known as a meet-in-the-middle attack. If we know one pair of \((P,C)\), then the attack can be carried out by first encrypting \(P\) with all \(2^56\) keys for \(K1\). Following this, \(C\) is decrypted with all \(2^56\) keys for \(K2\). If in this attempt, we have \(E_{K1}(P) = D_{K2}(C)\), then we are highly likely to have found both keys. This takes \(O(2^{56} + 2^{56} = 2^{57})\) steps, so only twice as long as DES.
The only issue with this attack is that it requires on the order of \(2^{56}\) memory. This can be split into smaller batches and ran efficiently by an attacker with only \(2^{45}\) memory. I won't go into further detail here but there's a good conceptual breakdown on the Cryptography StackExchange here.
Triple DES with Two Keys
Triple DES can be done with \(C = E_{K1}(E_{K2}(E_{K3(P)))\). In practice, this can be done with two keys, if we first encrypt with key 1, then decrypt with key 2, then encrypt again with key 1. This is called EDE.
This mode of encryption provides backwards compatibility with standard DES, as we would encrypt, then decrypt, then encrypt again with \(K1 = K2\).
Meet-in-the-Middle Attack
This is similar to the attack on 2DES. We encrypt with all possible keys for \(K1\), producing \(A\) from \(P\). From here, we can simply do a meet-in-the-middle attack on the remaining 2DES, with all \(A\) and all \(C\), to see if the decryption of \(A\) with \(K2\) yields the same as the decryption of \(C\) with \(K1\). This takes \(\approx O(2^{2k})\) steps on average.
AES
In 1997, NIST wanted to create a new standard for encryption as DES had been broken. AES would be unclassified and publicly disclosed, available royalty-free to everyone. The algorithms would be symmetric and block-based and able to support 128, 192, and 256 bit key sizes.
9 months later, there were 15 different designs for this standard submitted. These were narrowed down to the top 5: MARS, RC6, Rijndael, Serpent and Twofish. This happened in the AES2 conference in 1999.
Following this conference, in 2003, at AES3, there was a representative from each of the final five teams, and they each argued as to why their design should be AES. In 2000, NIST announced that Rijndael had been selected as the proposed AES.
The Algorithm (Encryption/Decryption)
Tip
There is a good online "PowerPoint" that covers this here. This goes through all the steps with examples.
AES is a substitution-permutation based network, and unlike DES doesn't rely on a Feistel network. Decryption is the inverse function of each step, meaning that each function must be invertible.
AES has a block size of 128 bits, which is divided into 16 bytes. Each of the 16 bytes is stored in a 4x4 matrix, known as the state, which holds the current data block:
Each of these elements is a standard 8-bit byte, and these are viewed as elements of the Galois field \(GF(2^8)\). A Galois field is also known as a finite field, and the Wikipedia page on this explains it well.
These bits are then considered a polynomial from constant up to \(x^7\), with the first bit being the \(x^7\), the next being \(x^6\), to \(x^0=1\). If the bit is set then the term exists in the overall polynomial.
There are multiple arithmetic operations that we can use on these. We can use addition with XOR \(\oplus\), multiplication with a modular using a prime polynomial. To multiply two elements, we multiply their polynomials, then divide by a specified prime polynomial. The remainder of this is the answer in terms of the multiplication.
Overview
The algorithm has specified round keys, which are explained later in this document. Each round comprises several steps, which are repeated for rounds 1-9, with a final byte substitution, shift row, and round key.
This means we have 10 round keys, and 9 repeated rounds. A (very poorly drawn) flowchart is shown below:
graph LR
A("Key (Round 0)") ---> B[Add Round Key]
B --> C[Byte Substitution]
subgraph "Each Round"
C --> D[Shift Row]
D --> E[Mix Column]
E --> F[Add Round Key]
K("Key (Rounds 1-9)") --> F
end
F --> G("Final Round?")
G -->|No| C
G -->|Yes| H[Byte Substitution]
H --> I[Shift Row]
I --> J[Add Round Key]
L("Key (Round 10)") --> JByte Substitution
Each byte in the data block of the state matrix is substituted with another byte, such that:
Here, $a^{-1} is the multiplicative inverse of \(a\) in the Galois field \(GF(2^8) \mod (X^8 + X^4 + X^3 + X + 1)\). This can generate a lookup table, so that we don't have to compute it every time, and this lookup table contains the row as the most significant nibble, with the column as the least significant nibble.
These lookup tables are published, and we can see that the row beginning 70 with a as the column, we yield da.
00 01 02 03 04 05 06 07 08 09 0a 0b 0c 0d 0e 0f
00 63 7c 77 7b f2 6b 6f c5 30 01 67 2b fe d7 ab 76
10 ca 82 c9 7d fa 59 47 f0 ad d4 a2 af 9c a4 72 c0
20 b7 fd 93 26 36 3f f7 cc 34 a5 e5 f1 71 d8 31 15
30 04 c7 23 c3 18 96 05 9a 07 12 80 e2 eb 27 b2 75
40 09 83 2c 1a 1b 6e 5a a0 52 3b d6 b3 29 e3 2f 84
50 53 d1 00 ed 20 fc b1 5b 6a cb be 39 4a 4c 58 cf
60 d0 ef aa fb 43 4d 33 85 45 f9 02 7f 50 3c 9f a8
70 51 a3 40 8f 92 9d 38 f5 bc b6 da 21 10 ff f3 d2
80 cd 0c 13 ec 5f 97 44 17 c4 a7 7e 3d 64 5d 19 73
90 60 81 4f dc 22 2a 90 88 46 ee b8 14 de 5e 0b db
a0 e0 32 3a 0a 49 06 24 5c c2 d3 ac 62 91 95 e4 79
b0 e7 c8 37 6d 8d d5 4e a9 6c 56 f4 ea 65 7a ae 08
c0 ba 78 25 2e 1c a6 b4 c6 e8 dd 74 1f 4b bd 8b 8a
d0 70 3e b5 66 48 03 f6 0e 61 35 57 b9 86 c1 1d 9e
e0 e1 f8 98 11 69 d9 8e 94 9b 1e 87 e9 ce 55 28 df
f0 8c a1 89 0d bf e6 42 68 41 99 2d 0f b0 54 bb 16
Shift Rows
Shift rows are cyclic shifts to the left, and have offsets \(0,1,2,3\). These happen immediately after the byte substitutions. We can imagine the state initially as \(A\), then transforming to \(B\), then transforming to \(C\) through this cyclic shift. This cyclic left shift can be envisaged as follows:
Mix Column
Now we have matrix \(C\) after the shift row, we need to obtain the matrix \(D\). This matrix is a left multiply of the \(C\) matrix by a specific mix matrix:
The multiplications in this case are \(GF(2^8)\).
Add Round Key
This is the final part of the AES round and is the XOR of each of the fields in the matrix with the key:
Key Schedule
The AES key schedule is a way to derive the round keys from the initial AES key with a fixed length. The original key, as seen above, has 4 columns and 4 rows, with the key at round \(i\) being \((W(4i), W(4i+1), W(4i+2), W(4i+3))\). This means that when we have the first round we take the original key, the second round is a 'new' 4x4 matrix to the right, which is created based on the original key.
When we generate a new round key, we have round constants, which we compose with the \(i-4\)th values of the key, then XORed with the column to its left or depending if it is the start of a round, then it is mixed with the round constant and rotated through. This function is known as \(T\), and the columnar matrix is known as \(W\). The functions are:
There is also that \(T\) function, and this is a transformation cyclically, such that we get \((b, c, d, a)^T\). We then replace each byte with the S-box entry for that byte to get \((e,f,g,h)^T\).
Above, I have already detailed the round constant which is \(r(i)\). Then, we can compute \(T(W(i-1) = (e \oplus r(i),f,g,h)\).
Implementation Options
AES is an algorithm that benefits from lookup tables and hardware acceleration. At the most basic level, there is an implementation that simply uses the pure mathematical definitions of the functions, and doesn't pre-compute anything. For example, instead of looking at the row and column in the S-box, we would compute the row and column as and when needed. This would be the typical implementation on a memory and space constrained device.
As we move up the chain, we can pre-compute the S-box and then call the lookup table. This is common on desktop machines and tablets. Finally, further up the chain, we can pre-compute the round functions using the lookup table. This is good where we need very high throughput, but it will use more memory initially to do all these computations.
Design Considerations
AES only needs to run for two rounds to fully diffuse the key into the data. This is done as we substitute, mix column and shift row.
The number of rounds was chosen to be 10 for the AES-128 implementation, as there are attacks that are better than brute force for up to six rounds. Anything that is better than brute force reduces the effective security of the cipher.
Furthermore, the key schedule chosen is a non-linear mix of the key bits, as this reduces the attack surface from where a cryptanalyst knows a part of the key and tries to deduce the remaining bits. The schedule also aims to ensure that if we have two distinct keys, then there is not a large number of round keys that they share.
Standardisation
AES is standardised by NIST and the standard can be found on the NIST website here. As mentioned earlier, this was done after heavy consultation with the cryptography community and a lengthy selection process.
Unlike DES, AES has extensibility built into the standard from the start. It specifies a different number of key bits, ranging from 128 to 256 bits, with 256 bits being quite expensive to implement initially but to allow users to change from AES-128 to AES-192 or AES-256 as hardware implementations got faster.
Comparisons to DES
AES was designed as the successor protocol to DES. Therefore, the shortcomings of the design of DES have been addressed, including longer key lengths, the encryption primitives used, and the design rationale.
The selection process for this was kept a secret, although NIST allowed comment publicly so that people could let NIST know of their concerns. The source for this standard was
Aside: Pi Pico HSM Implementation
As the implementation options were discussed, I was wondering if anyone had attempted to implement or benchmark AES on the Pi Pico. When looking at this, I found a project that turns a Raspberry Pi Pico into a hardware security module, capable of encryption and decryption of AES, RSA, and many others. This seems like a cool project that would be good to aid understanding, and implement a cheap-ish HSM. The project can be found on GitHub here.
Securely Using Block Ciphers
Block ciphers work with fixed sized blocks of data. For example, DES encrypts 64 bits of data per block, and AES ranges from 128 to 256 bits per block. We therefore encounter issues if the data size is not perfectly divisible by the block size, e.g., 1000 bytes.
We need to remember the security of a PRP function, such that it is secure if for all efficient algorithms we have no advantage from a key \(A\) and encryption algorithm \(E\). The attacker should not be able to distinguish between differing encrypted messages.
Naïvely Breaking Plaintext into Blocks
Initially, we might think to break the plaintext into blocks of the same size as the block size for the algorithm. We could then encrypt each block independently of the other blocks, such that \(C_i = E_K(P_i)\). This then effectively gives us a large electronic code book, or ECB.
This ECB then potentially contains several duplicate entries. Despite the plaintext being encrypted, we can then establish where there are repeated blocks within the text. Furthermore, if the same message is encrypted with the same key and sent twice, the cipher texts are the same. This could lead to significant attacks if the message space \(M\) is small.
ECB can only be used securely if the message length is equal to the data block length, and the key is changed for each message. Otherwise, we need a way to use the same key to encrypt many blocks but without changing the key. If this is not done, then the system is prone to chosen plaintext attacks, where the attacker is able to obtain the encryption of arbitrary messages of their choice and deduce the secret key.
In both DES and AES, if we get one \((c,m)\) pair, then this is enough to find the key if we exhaustively search the keyspace.
Semantic Security of PRPs with Many-Time Keys
Recall that we discussed PRPs above, and that we need to ensure an encryption function is secure. It will only be secure if the attackers are unable to distinguish between the encrypted messages, and one way to do this is to change the effective key used for each block.
The way we manage this effective key changing is through the use of a block cipher mode, which is an algorithm for generating a new effective key.
Block Cipher Modes
Within AES, NIST have approved 4 main modes of the cipher. There is a list of these cipher modes on the NIST website here, and each of them does something different to get the effective key for the next block.
Cipher Block Chaining Mode (CBC)
This mode takes an "IV" or initial vector, which is XORed with the plaintext before passing to the encryption function. After encrypting the first block, the ciphertext for this block is then XORed with the plaintext for the second block, to yield the ciphertext for that block.
This creates a chain of chaos which means that the plaintext goes through a round of XOR before being passed in to the AES function. This means that the same plaintext will never produce the same ciphertext, unless the previous rounds ciphertext is the same. Mathematically, this is as follows:
This works fine if we are transmitting lots of blocks in a row, as we need to compute the last block's ciphertext before we encrypt the next block. CBC seems like it would work okay, but has issues in that it is also prone to chosen plaintext attacks. Furthermore, errors in computation or transmission propagate so these need to be handled either by a lower layer, or in the transmission itself.
The IV also needs to be known to the sender and receiver as this is either a fixed value or sent encrypted using ECB mode before the rest of the message.
Chosen Plaintext Attacks
If we have \(E\) is a secure encryption over \((K,X)\), \(E_{CBC}\) is the CBC mode implementation of \(E\). The upper bound \(O\) of the advantage of the attackers using a chosen plaintext attack of \(E_{CBC}\) is: $$ Adv_{CPA}[A,E_{CBC}] \le 2 \cdot Adv[A,E] + \frac{2q^2L^2}{|X|} \forall |X| > 0 $$
The \(Adv\) function is the upper bound of the attackers of \(E\). \(q\) is the number of messages encrypted with the same key, \(L\) is the max length of the message, \(|X|\) is the size of the plaintext set.
Therefore, \(E_{CBC}\) is semantically secure, as long as \(q^2L^2 \ll |X|\). If we want \(Adv_{CPA}[A,E_{CBC}] \le 1/2^{40}\) and \(Adv_{PRP}[A,E]\) to be negligible, then we need \(q^2L^2 / |X| < 1/2^{40}\).
For AES, with \(|X| = 2^{128}\), we need to rekey such that \(q^2L^2/2^{128} < 1/2^{40}\). This means \(q^2L^2 < 2^{68}\), or \(qL < 2^{44}\). For 3DES, with \(|X| = 2^{64}\), this would mean rekeying after \(2^{12}\) blocks.
Counter Mode (CTR)
TIn this mode, a counter is initialized to some IV, then incremented by 1 for each block. The counter is encrypted, then XORed with the plaintext for that block:
Weaknesses of this include that the same key is used for all blocks, making it prone to CPA. The IV should also not be reused. Strengths of this approach include that we need only the encryption algorithm, and not the previous blocks. We can also parallelise our encryption, so this is better for high throughput links.
CTR is also semantically secure under CPA, provided \(q^2L \ll |X|\).
Cipher Feedback Mode (CFB)
This mode uses the entire output of the block cipher in its simplest form. The ciphertext \(C_i\) is either the IV or \(E_J(C_{i-1}) \oplus P_i\) after initialization. The plaintext \(P_i = E_K(C_{i-1}) \oplus C_i\). (Image from Wikipedia, Public Domain, author WhiteTimberwolf)
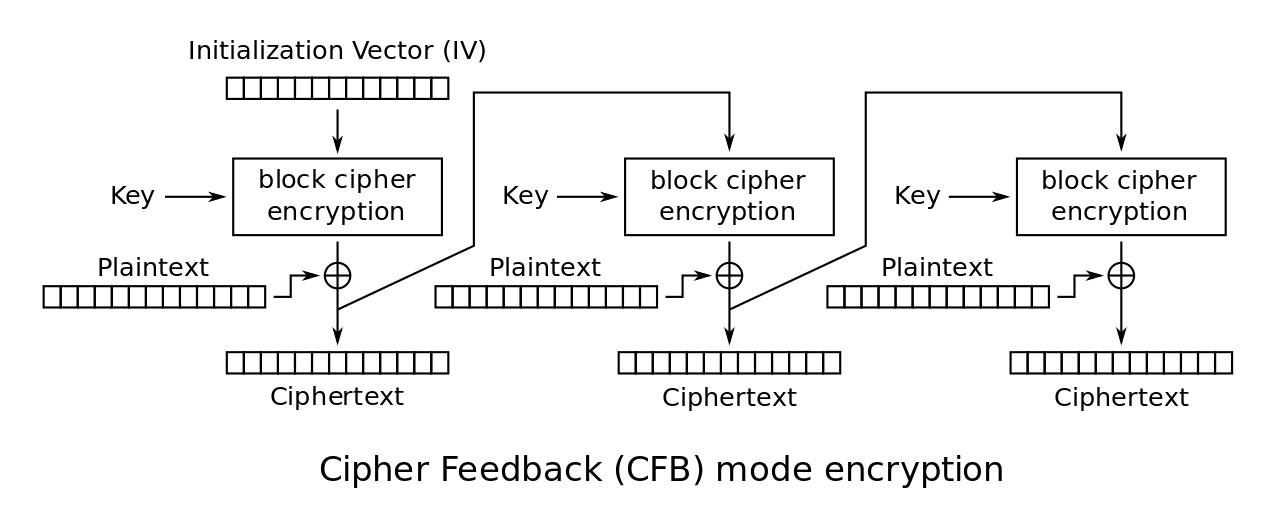
This mode can also be used discarding some parts of the IV or the ciphertext used for the next encryption. The lecture slides show us picking \(b-s\) bits from a shift register (e.g., 64 bits), then encrypting, selecting \(s\) bits, then combining with a plaintext \(P_i\) of length \(s\) and performing XOR over the plaintext.
For decryption, we can feed in the ciphertext at each iteration instead of the plaintext, which is then put into the shift register, encrypted with the key, then has \(s\) bits selected, then XORed again.
CFB is used as a stream cipher and is appropriate where the data arrives in bits or bytes. \(s\) can be any value we choose, typically \(s=8\). The segment then depends on the current and all preceding plaintext segments, so a corrupted segment will affect the current and next several plaintext segments.
Output Feedback Mode (OFB)
This is similar to cipher feedback, but instead of streaming the XORed data to the input of the next block in the chain, we send the selected \(s\) bits into the shift register. (Image from Wikipedia, Public Domain, author WhiteTimberwolf)

Attacks on Block Ciphers
Cryptographers categorise attacks on block ciphers into different types, each of which has varying complexities.
Ciphertext Only Attack
The adversary tries to deduce the key by only observing the ciphertext. If an encryption scheme is vulnerable to this type of attack, then it is considered completely insecure.
Known-Plaintext Attack
The adversary knows a quantity of plaintext and a corresponding quantity of ciphertext. This type of attack is only slightly more difficult, e.g., meet in the middle attack on DES.
Chosen Plaintext Attack
The adversary chooses a plaintext and then gets the corresponding ciphertext. They can then use any information from this to recover the plaintext corresponding to the previously unseen ciphertext.
Side Channel Attacks
These were covered more comprehensively in COMP3217: Cyber Physical Systems (Section 0.5). This is where we analyse the information leaked from the physical implementation of the system, e.g., EM radiation, power consumption, sounds, timing, heat, design details, etc.
Power analysis attacks exploit the correlation between the power consumption of the cipher hardware and the data being processed.
Quantum Attacks
Given a generic search problem, e.g., \(f: X \to \{0,1\}\), we want to find \(x \in X | f(x) = 1\).
A classical computer in the best case can only compute this in \(O(|X|)\). A quantum computer (as described in Grover, 1996) can do this in \(O(|X|^{1/2})\). Therefore, given \(m\) and \(c = E(k,m)\), we define:
If we have a quantum computer that can be built to do this, then we can break DES in \(2^{28}\) and AES-128 in \(2^{64}\), which would be doable if the price of quantum computing went down a lot.
Therefore, we are now moving to the more quantum-resistant AES-256 cipher.